1. startupProbe: 처음 가동 중일 때 ready라는 api를 앱으로 날린다. 한 번이라도 응답하면 readinessProbe와 livenessProbe에 반복적으로 api를 날린다.
2. readinessProbe: 외부 트래픽을 파드가 받을 수 있는 상태로 만들어주면서 서비스가 활성화되는 역할
3. livenessProbe: 앱이 살아 있는지를 체크하는 역할입니다. 만약 앱이 장애가 발생하게 되면 API는 실패하게 되고 아래의 경우의 예처럼 2번을 실패하게 되면 Kubernetes 앱 재기동을 한다.
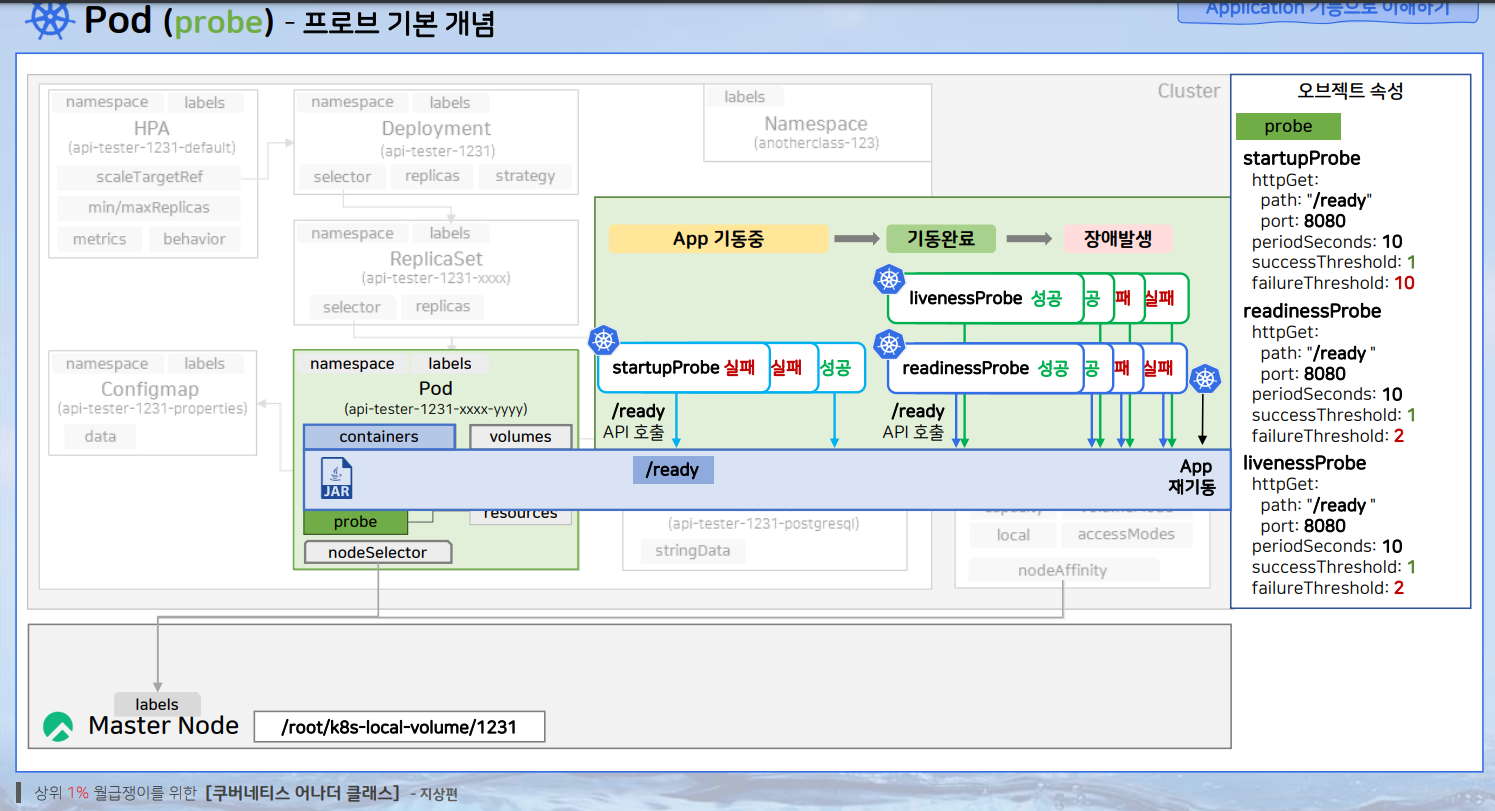
Application 동작 중심의 프로브 이해
쿠버네티스는 어플리케이션을 편하게 관리하기 위해서 만들어진거고요
어플리케이션 동작을 자동화해준다.
<APP 초기화>
모든 앱에는 초기화 과정이 있습니다. 파드가 생성되고 컨테이너 내부에는 JAR 파일이 실행되면서 내부에 있는 스프링이 초기화되는 과정이 있고 DB도 연결돼야지 앱이 모두 초기화된 거고 트래픽을 받을 수 있는 준비를 마친거죠.
<User 초기화>
다음으로 사용자가 앱에 초기 데이터를 로딩한다든지 이 앱을 필수로 연결시켜야 되는 시스템이 있어서 그 앱이 살아 있는지를 체크해야 될 수도 있을 거고 DB데이터의 필수 값들에는 문제가 없는지 밸리데이션도 함
결국 사용자 초기화 과정까지 끝나야 앱이 정확하기 기동을 한 거고 이후부터 트래픽이 들어와야지 제대로 된 응답을 줄 수 있는건데 그럼 여기까지 상황에서 필요한 자동화 기능이 뭔지를 보면 앱이 초기화 할 때는 시스템적으로 API를 받을 수 없는 상태이다. 이때 필요한 앱 상태 체크 기능의 목적은 초기화가 다 끝났는지를 아는거고, Health Check API를 한 번씩 보내봐서 200 OK가 오는 지 판단하는 동작으로 알 수 있을거다. 이 과정에서 외부 API 접근 금지 시켜야 한다.
한 마디로.... User초기화는 DB 데이터 검증, 연동 시스템 체크와 같은 단계를 거친다.
이때 외부 api는 받을 수 없고, 모든 초기화 과정이 끝났는지 확인하는 법은 health check api 보내서 200 ok 로 판단한다.
<APP 기동>
- APP 상태 체크 (APP이 살아 있는지)
- 외부 API 접근 허용
<APP 재기동>
앱이 죽으면 재기동

<Kubernets 동작>
쿠버네티스에는 이러한 애플리케이션 동작들을 다 자동화 해주었다.
쿠버네티스가 API를 계속 날리면서 앱 초기화가 끝났는지를 판단해줍니다. 그리고 Service와 Pod는 Selector와 Lable로 잘 맵핑을 해놨지만 Kubernetes는 실제로 이것을 미리 연결해 놓지는 않아요.
그리고 Startup Probe가 성공하면 Kubernetes는 Startup Probe 기능을 중지시키고 Liveness Probe랑 Readiness Probe 기능을 활성화시키는데 Liveness Probe 는 API 를 계속 호출을 하면서 앱이 잘 살아 잇는지 판단하고 만약에 API가 실패되면 장애라고 판단하고 파드를 재기동 시킵니다.
그리고 Readiness Probe는 앱에서 API 결과가 실패로 떨어지는 동안 여전히 서비스를 파드에 연결하지 않고 있다가 성공을 하면 이때 Kubernetes가 두 오브젝트를 연결하고 트래픽이 들어오게 돼요. (ex. 서비스와 파드 연결)
이때 트래픽이 들어오게 됩니다.
readiness probe는 유저 초기화 과정을 위해서 앱은 기동이 됐지만 의도적으로 외부 트래픽을 받지 않게 할 때 쓰는 거다.
이럴 의도가 없으면 Liveness Probe랑 Readiness Probe를 똑같은 API를 써도 무방하다.
그리고 이 2가지는 죽을때 까지 health 체크를 하기 때문에 최대한 가볍게 만들어야 된다.
< API 날려보며 프로브 동작 확인하기>

▶ Master Node에서 실행
// 1번 API - 외부 API 실패(앱 초기화 중이라서 실패)
curl http://192.168.56.30:31231/hello
// 2번 API
// 외부 API 실패
curl http://192.168.56.30:31231/hello
// 내부 API 성공 (유저 초기화 과정에서는 내부 api는 성공)
kubectl exec -n anotherclass-123 -it api-tester-1231-7459cd7df-2hdhk -- curl localhost:8080/hello
kubectl exec -n anotherclass-123 -it <my-pod-name> -- curl localhost:8080/hello
// 3번 API - 외부 API 성공 (앱이 기동되어서 성공)
curl http://192.168.56.30:31231/hello
// 4번 API
// 트래픽 중단 - (App 내부 isAppReady를 False로 바꿈)
curl http://192.168.56.30:31231/traffic-off
// 외부 API 실패
curl http://192.168.56.30:31231/hello
// 트래픽 재개 - (App 내부 isAppReady를 True로 바꿈)
(아래의 명령어는 dashboard에서 파드 옆의 콩3개의 exec 버튼을 눌러도 가능하다 그때는 curl localhost:8080/traffic-on 넣어주면 된다.
)
kubectl exec -n anotherclass-123 -it api-tester-1231-7459cd7df-2hdhk -- curl localhost:8080/traffic-on
//외부 API 성공
curl http://192.168.56.30:31231/hello
// 5번 API - 장애발생 (App 내부 isAppLive를 False로 바꿈)
curl http://192.168.56.30:31231/server-errorBash
GRAFANA로그를 보면 아래의 로그 처럼 readinessProbe 가 3번 실패를 서비스와 파드간의 연결이 끊긴다.


GRAFANA로그를 보면 아래의 로그 처럼 liveness Probe가 3번 실패를 하면 파드가 재기동된다.


일시적인 장애 상황에서의 프로브 활용

앱이 잘 기능돼서 서비스 중인 상태인데 일시적인 장애가 발생하였습니다.
그럼 앱의 부하가 높아지고 잠깐 렉이 걸리거나 스레드풀이 찰 수 있습니다. 또 이순간에 외부 API가 계속 들어오면서 불난 곳에 기름을 계속 붓습니다.
그래서 이러다가 시스템이 멈출 수도 있고 시간이 지나다 보면 스스로 해결이 될 수도 있습니다. 근데 이 과정에서 liveness, readness Probe가 실패를 하게 되면 Kubernetes는 파드를 재기동시킵니다.
이때는 오히려 프로브 기능이 없었으면 앱이 정상으로 돌아올 수 있는 상황에서 프로브가 파드를 재기동시켜버리면서 이 앱에서 처리 중인 작업들은 모두 실패가 될 수 있습니다. (실패하지 않고 모두 오나료시키는 방법 graceful shutdown이 있음)
이러한 상황을 해소하기 위해서 일시적인 부하 상황에서 readnessProbe 실패 시에 외부 API 접근을 금지시키고 앱에 추가적인 부담을 감소시키기 때문에 그대로 둬도 됩니다.
livenessProbe를 readnessProbe랑 같이 않게 하는 부분이 포인트입니다.
실패하는데 걸리는 시간을 좀 더 길게 설정해서 재기동되는 것을 조금 더 지원을 시키면 됩니다. 여기서 얼마나 지연 시킬지에 대해서는 각자 어플리케이션마다 시스템 관리 정책을 세워야되는 부분입니다.
위 자료는 쿠버네티스 어나더 클래스(지상편) - Sprint1의 강의를 듣고 정리한 자료입니다.
https://www.inflearn.com/course/%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4-%EC%96%B4%EB%82%98%EB%8D%94-%ED%81%B4%EB%9E%98%EC%8A%A4-%EC%A7%80%EC%83%81%ED%8E%B8-sprint1/dashboard